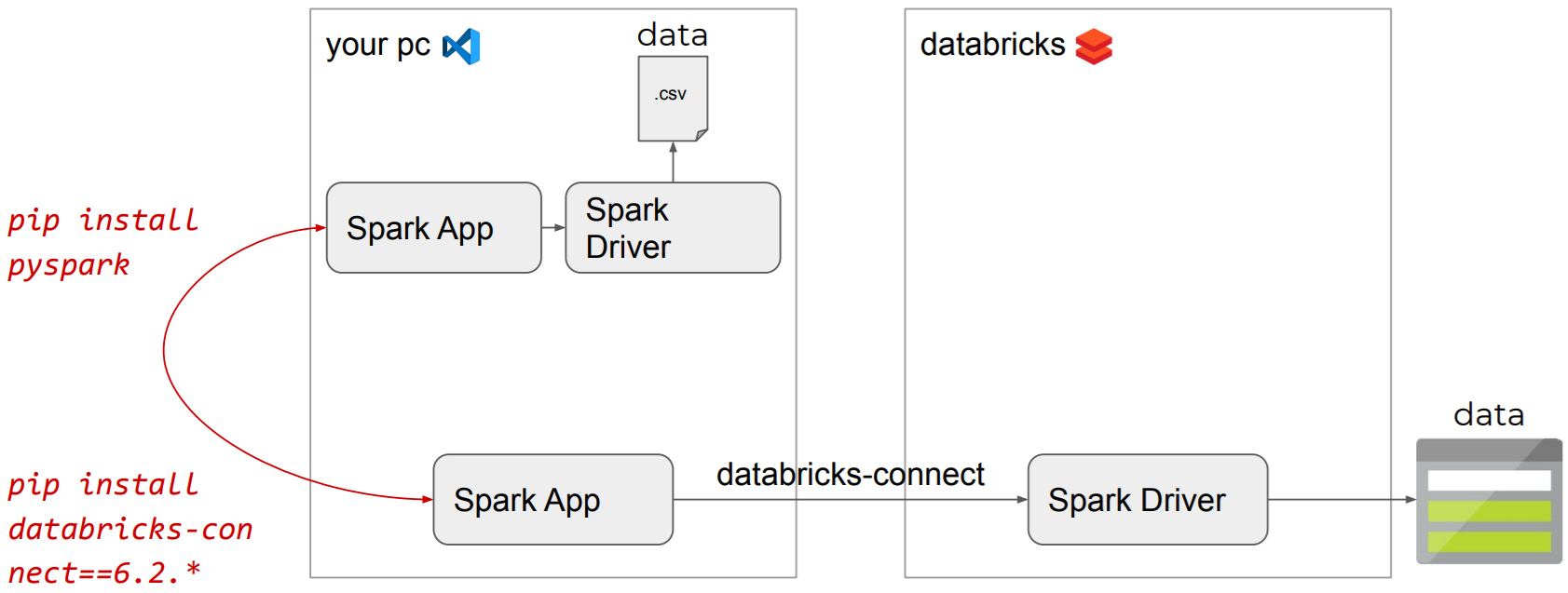
Install databricks-connect
Databricks-connect allows you to connect your favorite IDE to your Databricks cluster.
![]() ⟶
⟶ ![]()
Visit your Databricks cluster page, and verify that your cluster supports python3, then add the following lines to the Spark Config:
spark.databricks.service.server.enabled true # required with Runtime version 5.3 or belowspark.databricks.service.port 8787
Install Java on your local machine:
apt install openjdk-8-jdk
Uninstall any pyspark versions, and install databricks-connect using the regular pip commands, preventing any changes to be recorded to your virtual environment (prevents mutations to Pipfile and Pipfile.lock):
pip uninstall pyspark
pip install -U databricks-connect=="6.2.*" # this version should match your Databricks Runtime Version
If you want to switch back to pyspark, simply do the exact opposite:
We’ll have to set up our ~/databricks-connect file once, containing our cluster information. Create and copy a token in your user settings in your Databricks workspace, then run databricks-connect configure on your machine:

You’ll need some information that you’ll find in the address bar when you visit your cluster page:

When you’ve filled in the information, you can run databricks-connect configure again to verify:
➜ databricks-connect configure
The current configuration is:
* Databricks Host: https://westeurope.azuredatabricks.net/
* Databricks Token: dapi5c376de3a2a54a2b03016c8c3b123456
* Cluster ID: 0214-195926-aptin821
* Org ID: 3892784943666666
* Port: 8787
Run databricks-connect test to test your installation. You’ll hopefully see something along the lines of:
➜ databricks-connect test
* PySpark is installed at /c/projects/demo-project/.venv/lib/python3.7/site-packages/pyspark
* Checking SPARK_HOME
* Checking java version
openjdk version "1.8.0_242"
OpenJDK Runtime Environment (build 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08)
OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)
* Testing scala command
20/02/18 08:08:32 WARN Utils: Your hostname, ANL-SS14 resolves to a loopback address: 127.0.1.1; using 172.17.254.209 instead (on interface eth1)
20/02/18 08:08:32 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/02/18 08:08:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
20/02/18 08:08:49 WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
20/02/18 08:09:08 WARN SparkClientManager: Cluster 0214-195926-aptin821 in state TERMINATED, waiting for it to start running...
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5-SNAPSHOT
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_242)
Type in expressions to have them evaluated.
Type :help for more information
...
* Testing python command
View job details at https://westeurope.azuredatabricks.net/?o=3892784943666666#/setting/clusters/0214-195926-aptin821/sparkUi
...
* Testing dbutils.fs
...
* All tests passed.
If you follow the link, you’ll see the db-connect executions as a result:

Finally, run pyspark from your terminal, and start developing spark apps using your favorite IDE / environment while using powerful clusters and big data!
pyspark